Trust engineering
Model risk management (MRM) can't oversee agents effectively. Harness engineering can
Most first time vibe coders are comforted by the frequency with which the coding agent pauses and asks for their permission before doing something.
These users know that they are the “human in the loop” and carefully read the trace of what the agent has done and scrutinize its request. They consider: Do I want to allow the agent to execute the recommended command? Then, with some trepidation, they click “yes” and watch with bated breath to see what happens next.
After doing this a few times, users get the courage to click on “Yes, for all instances like this,” which speeds things up a bit. Then they learn it is faster to hit the “1” key on their keyboard indicating “yes” rather than reaching for their mouse each time.
At some point users hit approval fatigue and tire of pressing “1”repeatedly. They learn that they can instruct their agents to “dangerously skip permissions” (yes, that’s the actual command in Claude Code). This allows the coding agent to run autonomously without seeking any approvals until the project is done.
This arc — from caution to familiarity to annoyance to let-it-rip! — is one that many users of coding agents travel. It also explains OpenClaw’s extraordinary popularity; as an “always on” agent, OpenClaw takes dangerously skip permissions to an extreme and does stuff for users 24/7 without seeking any approvals. While security concerns abound, its productivity has captured everyone’s attention. Jensen Huang, the CEO of Nvidia, recently called OpenClaw “the most important software release probably ever”. (Translation: fully autonomous, always on agents are going to change how everything works.)
This rapid evolution illustrates the challenge of sustaining human-in-the-loop oversight for agentic systems. Forcing a person to affirmatively approve every agentic action might feel prudent and align with human-in-the-loop sensibilities. But if in practice that person ends up impatiently clicking “yes” every time, it is worse than ineffective — it is the appearance of oversight without actual oversight.1
In banking, regulators have leaned heavily on model risk management (MRM) to provide oversight of quantitative models. MRM operates as a gatekeeping control. Model risk managers must approve new models and model changes before they can be deployed by a bank. They review model documentation for completeness, conduct validation tests, and ensure that all of the steps in the model life cycle have been followed before giving the green light. They would be natural candidates to be the human in the loop of an AI system.
As explained below, though, the MRM approach is not scalable or compatible with agent deployments. More worryingly, it is at risk of giving the appearance of oversight without its substance. To oversee agents effectively, we should let go of MRM. The risk with agent systems is not how the underlying models are specified or calibrated or documented. The risk lies in how agent systems are engineered. And to mitigate that, we must think like trust engineers, not expert gatekeepers.
The limits of model risk management
Model risk management arose in the late 1990s in response to the realization that incorrect model outputs could have significant safety and soundness consequences for banks. As recounted in “Model Risk and the Great Financial Crisis," MRM expanded from an initial focus on validation of a narrow set of capital-related models to documentation of the model life cycle for a wide range of quantitative calculations.
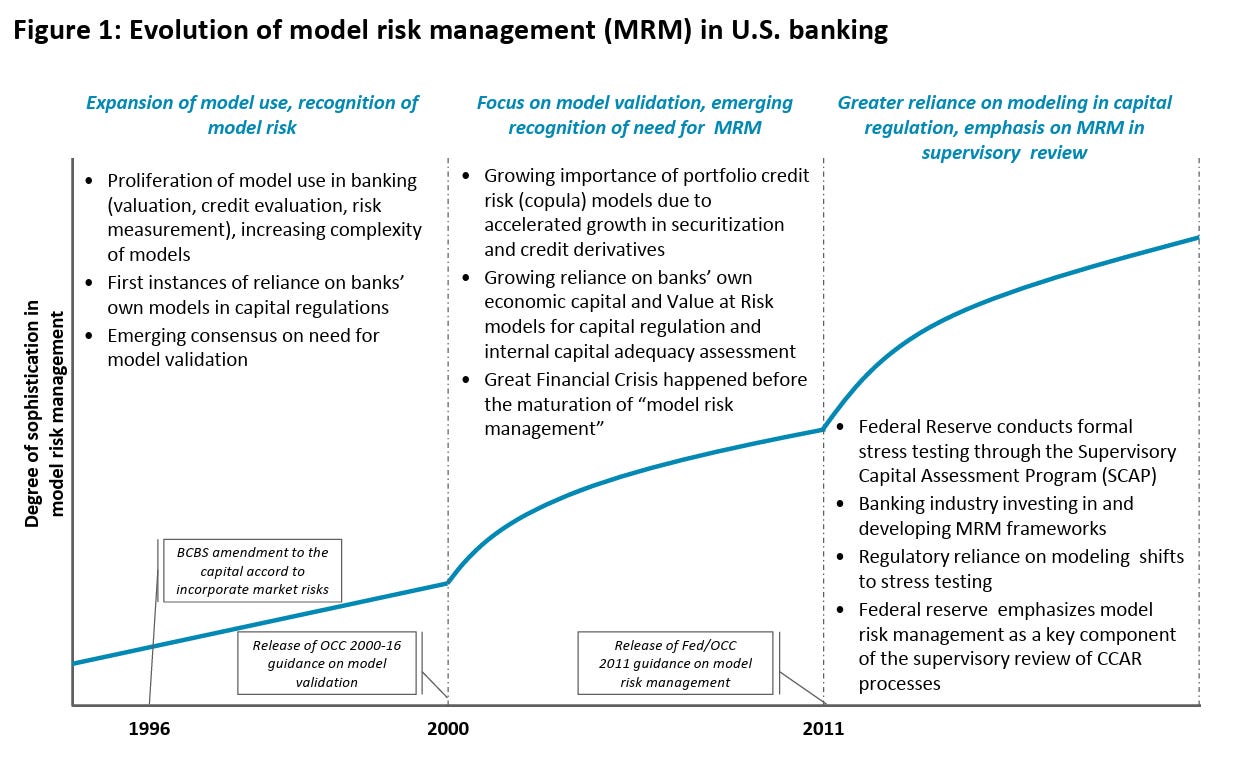
MRM can be effective for models that function as single-purpose calculators, where the inputs and outputs are of a specific type and form, e.g., for the calculation of credit scores, valuations, the Greeks, probabilities of default, or stress loss estimates. In such cases, outputs can be statistically validated by backtesting against historical data. Notably, banks have been able to effectively apply MRM to ML/AI algorithms for years where they fall within these criteria.
Large language models (LLMs) are not single-purpose calculators and they can’t be statistically validated. Their inputs and outputs are open ended and user-AI interactions can be dynamic. Users’ prompts can take a nearly infinite range of possibilities, as can LLMs’ outputs. MRM, which is heavily grounded in documentation and validation, was never designed to handle that.
MRM also presupposes that being able to interpret or explain how a model works is critical to governing it. That’s because when a model calculation is wrong, understanding how it works can inform the fix. As noted in my paper on AI actionability, though, LLMs are not yet interpretable in the classic sense. And even if they were and we knew exactly which parameters got activated for a given response, the transformer architecture underpinning LLMs does not allow model fixes in any practical sense.
These limits to MRM’s effectiveness for LLMs is exacerbated a thousand-fold for agents. In agentic systems, LLMs are equipped with context and the ability to use tools and take actions. The range of culprits for a bad outcome expand far beyond model performance. As noted in my paper:
[E]ven the simplest agents raise questions about the role and efficacy of interpretability analysis. For example, in the “Japanese cheesecake” hypothetical, an AI agent instructed to purchase ingredients for a Japanese cheesecake instead buys the user a plane ticket to Japan. Understanding why this might occur requires untangling interactions between the user prompt, the context, the agent system set up, and the underlying model – a task beyond the scope of traditional model interpretability.
The rise of harness engineering
Last year I laid out three approaches that banks could take to risk manage AI: (I) shoehorn it into existing model risk (MRM), software development (SDLC), and vendor (TPRM) frameworks, (II) integrate the three frameworks for specific AI use cases, or (III) establish a distinct risk management framework.
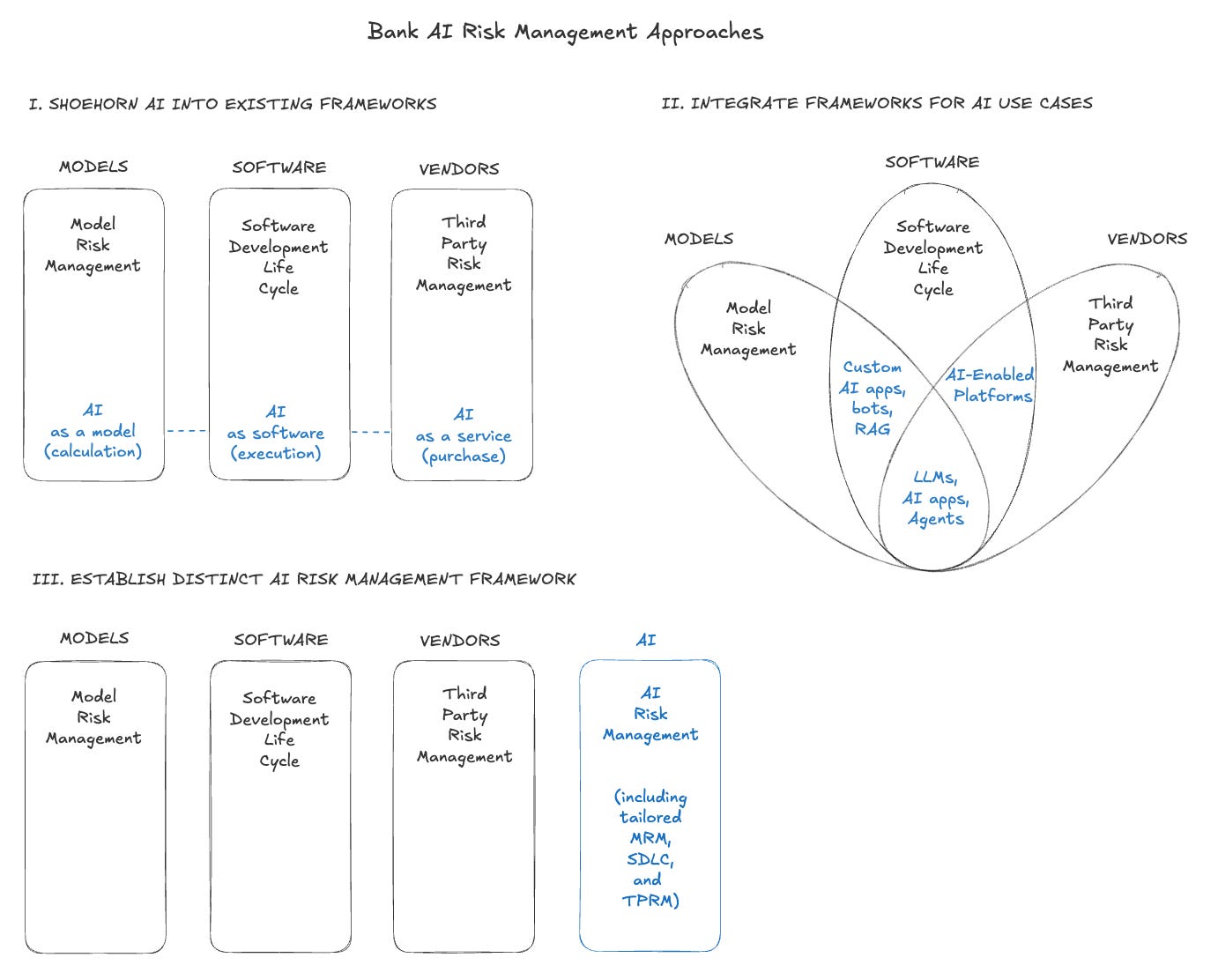
Notably, the leading AI labs and developers have embraced the third approach, marking a shift away from the traditional software development life cycle (SDLC). In a way, SDLC is to software as MRM is to models — it encompasses requirements, design, implementation, testing, review, and deployment and assumes that humans write code and that each phase should be gated by human approval. But similar to MRM, the SDLC framework doesn’t work for agents, which can autonomously plan and spin up working features in minutes.
Thus, for agents the frontier labs have ditched the software development mindset for an engineering mindset, focusing on the conditions and choices that determine the environment in which agents operate. Many refer to this as “harness engineering.”
The term harness is borrowed from equestrian and refers to the complete set of equipment — reins, saddle, bit — for guiding and controlling a powerful but unpredictable animal. In the AI context, a harness is the infrastructure around an LLM: the constraints, feedback loops, guiding documentation, source code checkers (linters), sandboxes, and verification systems that govern how an agent operates. The LLM supplies the reasoning. The harness supplies everything else.
The harness engineering paradigm rests on four pillars:
Context architecture. Structuring what information the agent sees at each step, so it operates within defined boundaries rather than wandering without proper context.
Architectural guardrails. Enforcing strict structural boundaries through automated checks, so agents cannot violate design constraints even when operating autonomously.
Verification systems. Automated testing, observability, and satisfaction scoring that continuously evaluate agent outputs without requiring a human reviewer to examine each action.
Feedback loops. Treating every agent failure as a signal to improve the harness itself, not just to fix the immediate error. When an agent struggles, the response is to identify what is missing — a tool, a guardrail, a piece of documentation — and feed it back into the system.
(Notably absent from this list are model interpretability, pre-deployment documentation reviews, and human approval gates.)
The harness engineering paradigm does not try to understand why the model produced a given output. It does not require a human to sign off before each action is taken. Instead, it builds an environment where the range of possible agent behaviors is constrained by design, deviations are detected automatically, and the system improves through use rather than through periodic reviews.
The harness engineering paradigm builds an environment where the range of possible agent behaviors is constrained by design, deviations are detected automatically, and the system improves through use rather than through periodic reviews.
This is the conceptual leap that banks and regulators needs to make. When a bank deploys an AI agent to process loan applications, monitor transactions, or generate regulatory reports, the question should not be “has a model risk manager reviewed and approved this model?” The question should be: What is the harness? What constraints bind the agent’s actions? What verification systems detect when it goes wrong? What feedback loops ensure the harness improves over time?
The feedback loop component is worth expanding on, as it is most distinct from the MRM/SDLC gatekeeping approach. In its guidance to developers on building agents, Anthropic describes the core agent loop as a tight cycle: gather context, take action, verify work, repeat. The verify work step is critical. Anthropic notes that models, left to their own devices, can declare a task complete without actually testing whether it works end to end. They found that only when the harness required the agent to verify its own output — through browser automation, screenshot validation, or full integration tests — did performance improve dramatically.
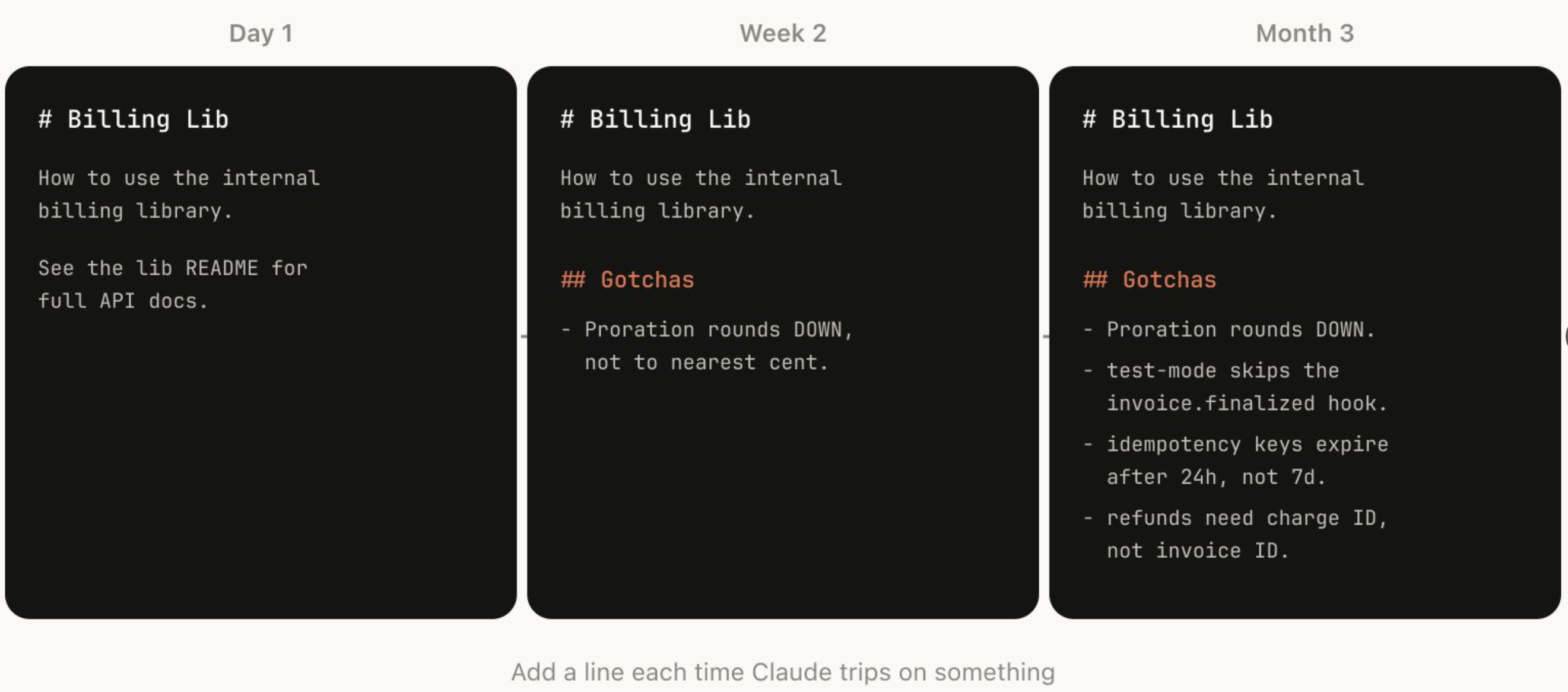
In house, Anthropic engineers go even further, building in “Gotcha sections” into the Skills that their agents use. The “gotchas” record specific agent failures so that the agent can learn and avoid repeating those mistakes in the future. This enables a feedback loop to bring those failures into the harness. The screenshot below shows the build up of “gotchas” over time for a sample Skill.
Simon Willison, a well-known programmer and AI safety researcher who coined the phrase “prompt injection,” recently reviewed the agent harness used by StrongDM, an access controls company. Willison was surprised initially by their approach which mandates that humans don’t write any code and don’t review any code — i.e., humans are taken completely out of the loop. Instead, StrongDM relies on robust harness engineering — e.g., scenario analyses, held out tests, digital twin universes — to embed vulnerability tests, fixes, and reliability into the agent system itself.
This echoes the lesson that both Anthropic and OpenAI learned when using agents to build their coding agents — namely, that verification must be built into the harness at the level of “did the system accomplish its objective?” not “did it follow the prescribed steps?”
Trust engineers
Adopting a harness engineering approach to overseeing agents requires a shift in the role of humans.
In the MRM paradigm, the human is an expert gatekeeper who reviews documentation and approves or rejects models.
In the harness engineering paradigm, the human is a trust engineer who designs the environment, defines the constraints, specifies the success criteria, monitors the system’s performance, and provides continuous feedback over time. The human’s job is not to grant or withhold permission every time an agent asks. The human’s job is to build a world in which the agent’s autonomy is bounded by design, where verification is continuous, automated, and grounded in outcomes, and feedback loops frequently.
The jobs are fundamentally different. A model risk manager’s power lies in their ability to approve or reject a model. A trust engineer’s power lies in their ability to build smarter context architectures, clearer guardrails, stronger verification tests, and better feedback loops. A model risk manager worries about making type 1 and type 2 errors — blocking models that are ok and approving models that will fail. A trust engineer worries about the effectiveness of the harness they’ve built and whether it needs adjusting.
My guess is that many supervisors’ and model risk managers’ reaction to this will be skepticism that such a significant change in needed. They will argue that MRM can be adapted to cover agents and all that’s really needed is a greater emphasis on monitoring and a de-emphasis of review and approvals.
The skeptics may be right and I invite the debate. The sharpest minds in AI and the labs with the most experience with agents, though, have moved on from SDLC gatekeeping to harness engineering. It is a move that regulators should carefully study and consider.
Anthropic’s recent release of Code Review has sparked a similar debate amongst professional developers and software engineers, with some noting that the same fiction has been building for years with regards to human review of pull requests.