Policy as code
The tools now exist to close the gap between regulatory intent and machine execution. Readers can test one out below

One day, we will look back and wonder how government was able to work effectively through PDFs
Title 12 of the Code of Federal Regulations (CFR) governs banks and banking. It has 18 chapters spanning multiple volumes and thousands of pages. Every proposed rule change — like the federal banking agencies’ recent Basel 3 reproposal — must be published in the Federal Register. When rules are finalized, Title 12 of the CFR gets updated.
All of those releases are all via PDFs.
The translation problem with PDFs
The Government Publishing Office’s adoption of PDFs in the 1990s coincided with the rise of the internet. In today’s day and age, though, the PDF is about as helpful as the punchcard.
For regs to be effective, they need to be able to be translated into verifiable actions, processes, and systems that match the requirements laid out in the rule. Traditionally, this has been done manually, with people reading reg text and translating it into what has to be done.
As the volume, granularity, and complexity of regs has expanded, though, this approach has come under strain. Put simply, there is a LOT to translate. And the more there is to translate, the more translation error there is.
In a previous post, I highlighted the problem of policy sludge — redundant, conflicting, misaligned, and stale rules, regs, and guidance. The risk of translation error expands exponentially with the accumulation of policy sludge. Part of the solution lies in cleaning up policy sludge. Part of it lies in reducing translation error.
PDFs are pictures. Humans may see words, but with PDFs computers just see pixels on a page. While there’s plenty of tech that can translate those pixels (back) into words that machines can read, that translation isn’t always perfect and the longer and more complex the documents, the more translation error there’s likely to be.
Releasing regs in machine-readable form, like Markdown, XML, or JSON, would mitigate most of these translation problems. Making regs API-queryable would nearly eliminate them.
To make this concrete, consider a single provision from MiFIR Article 26(1), a transaction reporting obligation:
“Investment firms which execute transactions in financial instruments shall report complete and accurate details of such transactions to the competent authority as quickly as possible, and no later than the close of the following working day.”
In a PDF, after extraction and parsing, that provision has irregular spacing, an orphaned page number, and no indication of which article it belongs to:
Investment firms which execute transactions in financial
instruments shall report complete and accurate details of
such transactions to the competent authority as quickly
as possible, and no later than the close of the
following working day.
26
In Markdown with YAML frontmatter, the same provision carries machine-readable context — i.e., who it applies to, what type of obligation it is, the deadline — without needing to parse any prose:
---
regulation: MiFIR
article: 26
paragraph: 1
title: Transaction Reporting Obligation
jurisdiction: EU
effective_date: 2018-01-03
obligation_type: reporting
subject: investment_firms
competent_authority: true
deadline: T+1
---
## Article 26 — Transaction Reporting
### 26(1) Obligation to Report
Investment firms which execute transactions in financial instruments
shall report complete and accurate details of such transactions to
the competent authority as quickly as possible, and no later than
the close of the following working day.
An LLM or rules engine querying “what is the reporting deadline under MiFIR Article 26?” gets T+1 directly from the metadata — no extraction, no interpretation, no translation error.
For readers who want to see the full progression from PDF through plain text, Markdown, XML, and JSON, the appendix walks through each format in detail. An interactive version involving AML/CDD and Basel 3 examples is also available here:
Converting policy to code
Academics have studied computational law and legal informatics for many years. Regulators have also been exploring machine-readable regs for some time, with the UK FCA being one of the first to launch a Digital Regulatory Reporting initiative back in 2017. Industry has also contributed, e.g., through FINOS’s Common Domain Model (CDM) for machine-readable and machine-executable trade reporting, which launched in 2023.
These have all been fairly narrow in scope, though. Why?
The core challenge is implementation. How does one convert regulatory text and tables into code? And who should do the converting? If law firms or fintechs or other third parties do it, can banks rely on it?
If the agency issuing the reg converted the reg text into code, it would eliminate the transmission loss between the agency’s intent and the downstream implementation. The agency’s judgment about what a provision means would be encoded directly, rather than filtered through layers of interpretation. But drafters of regulations are steeped in policy, not coding. They are fluent in statutes, regs, and rulewriting, not Markdown, XML, and JSON.
What if there was a tool that could help regulators convert policy to code as they were drafting? Imagine the tool having a drafting window that looked like Word, but was set up to format reg headers automatically, autofill sections and paragraphs using regulatory numbering conventions, and auto-link cross-section references and definitions.
By doing that, the tool would be able to convert the draft text into a machine-readable Markdown file automatically in real time. (Markdown files are simple text files, but have labeling and linkage conventions that are readable by machines.) This would be hugely helpful. When an analyst uploads the Basel 3 PDF to an LLM to analyze, the LLM sees 1,500 pages of pictures (pixels) and has to extract and parse it into words before it can do anything. That extraction is imperfect given page breaks, inconsistent section formatting, tables, etc. In Markdown, the LLM would see the reg exactly as it was intended — no extraction necessary.
With some metadata prep work, the tool could also automatically convert draft text into XML and JSON, which are structured coding languages. Instead of a person or LLM needing to identify, say, a a deadline of T+1 for a reporting obligation, the JSON would hard code it, eliminating the need to determine context and understand the meaning of what’s read. (See the appendix for a detailed example.)
Introducing the Policy-as-Code Editor
I built a prototype Policy-as-Code Editor for readers to experiment with.1 It comes pre-loaded with the first several sections of the Basel 3 proposed rule, but readers can insert or draft whatever reg text they want. The Editor automatically converts the text in the drafting window (left window) into three machine readable formats (right window). To help drafters maintain consistency and clarity within the draft reg text, the middle bottom window tracks internal cross-references, definitions, and enforceable obligations.
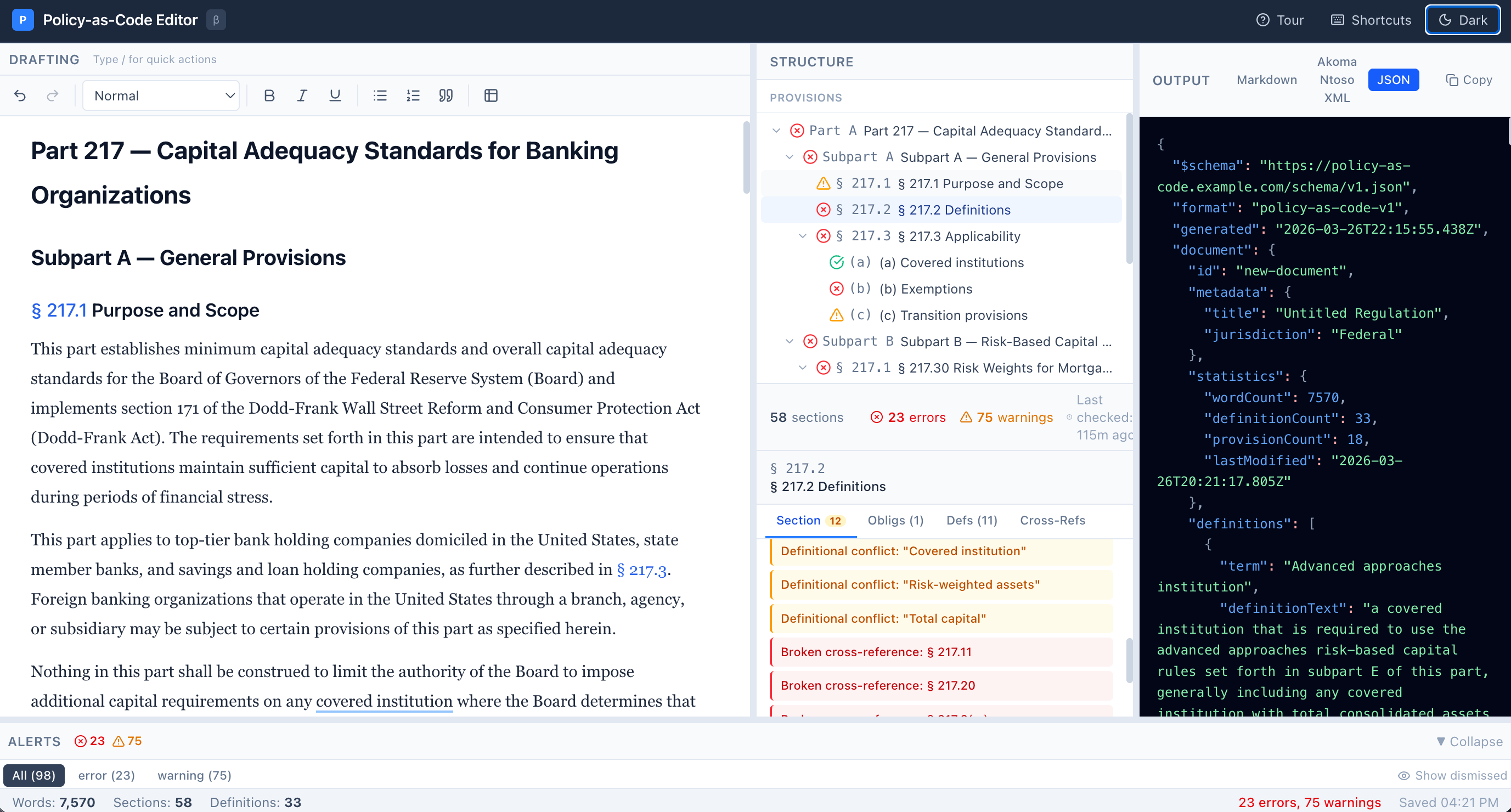
The design is modeled on coding IDEs like VS Code and Cursor. Code is highly structured and needs to be extremely precise to work as intended. IDEs help coders achieve that by providing all of the views and tools in a concise package. Regulatory text has some of the same properties — it is structured, must be precise, and its effectiveness depends on faithful downstream implementation. The policy-as-code editor adapts the IDE paradigm for rulewriting, putting the policy drafter at the center of the action. No hand offs. No intermediaries. Just a transparent and direct connection between policy and code, paired with tools to ensure that all of the policy and code pieces fit together.
In the prototype, I also mocked up a policy sludge co-pilot, so that when provisions and language in the drafting window conflict or overlap with other regs, flags go up in the alert window along the bottom. (The sludge co-pilot is based on work from another project I’m doing to identify policy sludge in the Basel 3 NPR. It won’t work more generally until an advanced policy sludge tool is developed.)
Where to go from here?
Regulators can and should take an initial step by releasing Markdown versions of all of the PDFs they release. This would eliminate the need for banks, law firms, and LLMs to extract and parse text from PDFs — eliminating one source of translation error. The risks to agencies of doing Markdown conversions are quite manageable. (The hardest part would be setting up the YAML frontmatter for each section of long rules, like Basel 3.)
Industry should focus on developing a cross-jurisdictional ontology that all regulators could adopt to enable XML and JSON representations of their regs. By standardizing how obligations, entities, deadlines, and cross-references are encoded across jurisdictions, such an ontology would allow XML/JSON conversions to scale beyond individual rule sets in individual jurisdictions. FINOS’s Common Domain Model may be a good starting point for this as it has proven to be effective in this regard for derivatives trade reporting.2
The workers in the 1965 photograph at the top of this post were operating keypunches — translating human-readable information into machine-readable punchcards, one keystroke at a time. Over time, we found better ways to get that information into machines. PDFs are today’s punchcards: a format that made sense in a prior era, but now stand between regulatory intent and regulatory execution. The tools to close that gap are here, enabled by AI. The question is when regulators will pick them up and whether industry will have done the work to enable cross-jurisdictional readability by the time they do.
Appendix — PDF vs Markdown vs XML vs JSON
This section shows in detail the differences between PDF, Markdown, XML, and JSON.3
Consider the following provision from MIFIR Article 26(1), a transaction reporting obligation:
“Investment firms which execute transactions in financial instruments shall report complete and accurate details of such transactions to the competent authority as quickly as possible, and no later than the close of the following working day.”
1. PDF
Investment firms which execute transactions in financial
instruments shall report complete and accurate details of
such transactions to the competent authority as quickly
as possible, and no later than the close of the
following working day.
26
This is a PDF after it has been extracted and parsed. Notice the irregular spacing, the page/article number orphaned at the end, and no indication that this is related to Article 26(1).
2. Plain Text
MiFIR Article 26(1)
Investment firms which execute transactions in financial instruments
shall report complete and accurate details of such transactions to
the competent authority as quickly as possible, and no later than
the close of the following working day.
This is readable with no noise. But it lacks context. An LLM may or may not know that this is an obligation and who it applies to.
3. Markdown with YAML Frontmatter
---
regulation: MiFIR
article: 26
paragraph: 1
title: Transaction Reporting Obligation
jurisdiction: EU
effective_date: 2018-01-03
obligation_type: reporting
subject: investment_firms
competent_authority: true
deadline: T+1
---
## Article 26 — Transaction Reporting
### 26(1) Obligation to Report
Investment firms which execute transactions in financial instruments
shall report complete and accurate details of such transactions to
the competent authority as quickly as possible, and no later than
the close of the following working day.
This now has context that is machine readable. An LLM knows who the rule applies to, what type of obligation it is, and the deadline — without reading the prose. The “YAML frontmatter” is queryable metadata. The Markdown is clean for search and retrieval.
4. XML (Akoma Ntoso)
<article eId="art_26" GUID="mifir-art26">
<num>26</num>
<heading>Transaction Reporting</heading>
<paragraph eId="art_26__para_1">
<num>1</num>
<content>
<p>
<entity refersTo="#investment_firm">Investment firms</entity>
which execute transactions in
<concept refersTo="#financial_instrument">financial instruments</concept>
shall
<obligation type="reporting" deadline="T+1"
recipient="#competent_authority">
report complete and accurate details of such transactions
to the competent authority as quickly as possible, and no
later than the close of the following working day
</obligation>.
</p>
</content>
</paragraph>
</article>
Note, here every element is tagged semantically. “Investment firms” resolves to a defined entity. The obligation has machine-readable attributes. An LLM or a rules engine can extract deadline="T+1" directly without parsing any prose.
5. JSON
{
"regulation": "MiFIR",
"article": 26,
"paragraph": 1,
"title": "Transaction Reporting Obligation",
"text": "Investment firms which execute transactions in financial instruments shall report complete and accurate details of such transactions to the competent authority as quickly as possible, and no later than the close of the following working day.",
"obligation": {
"type": "reporting",
"subject": "investment_firms",
"object": "transaction_details",
"accuracy_required": true,
"recipient": "competent_authority",
"deadline": {
"description": "close of following working day",
"standard": "T+1"
}
},
"cross_references": [],
"jurisdiction": "EU",
"effective_date": "2018-01-03"
}
This is the most machine-executable of all. The deadline is a structured field, not buried in a sentence. An agent querying “what is the reporting deadline under MiFIR Art 26?” gets T+1 directly.
I recently joined FINOS as an advisor. The views expressed here are my own and I did not consult with FINOS on this post.
Opus 4.6 helped with the details of this section.